Voice Recognition Engine testing
Project Manager
- Articifial Intelligence
- NLP
- Agile delivery
- Date: 2017
- Articifial Intelligence
- NLP
- Agile delivery
- Date: 2017
Description
As part of a larger partnership with NTT Data we embarked on a trial of a voice recognition engine which aimed to transcribe recorded speech, which was a ground-breaking technology at the time. We undertook a two stage trial and explored several use cases for the software.
Objective
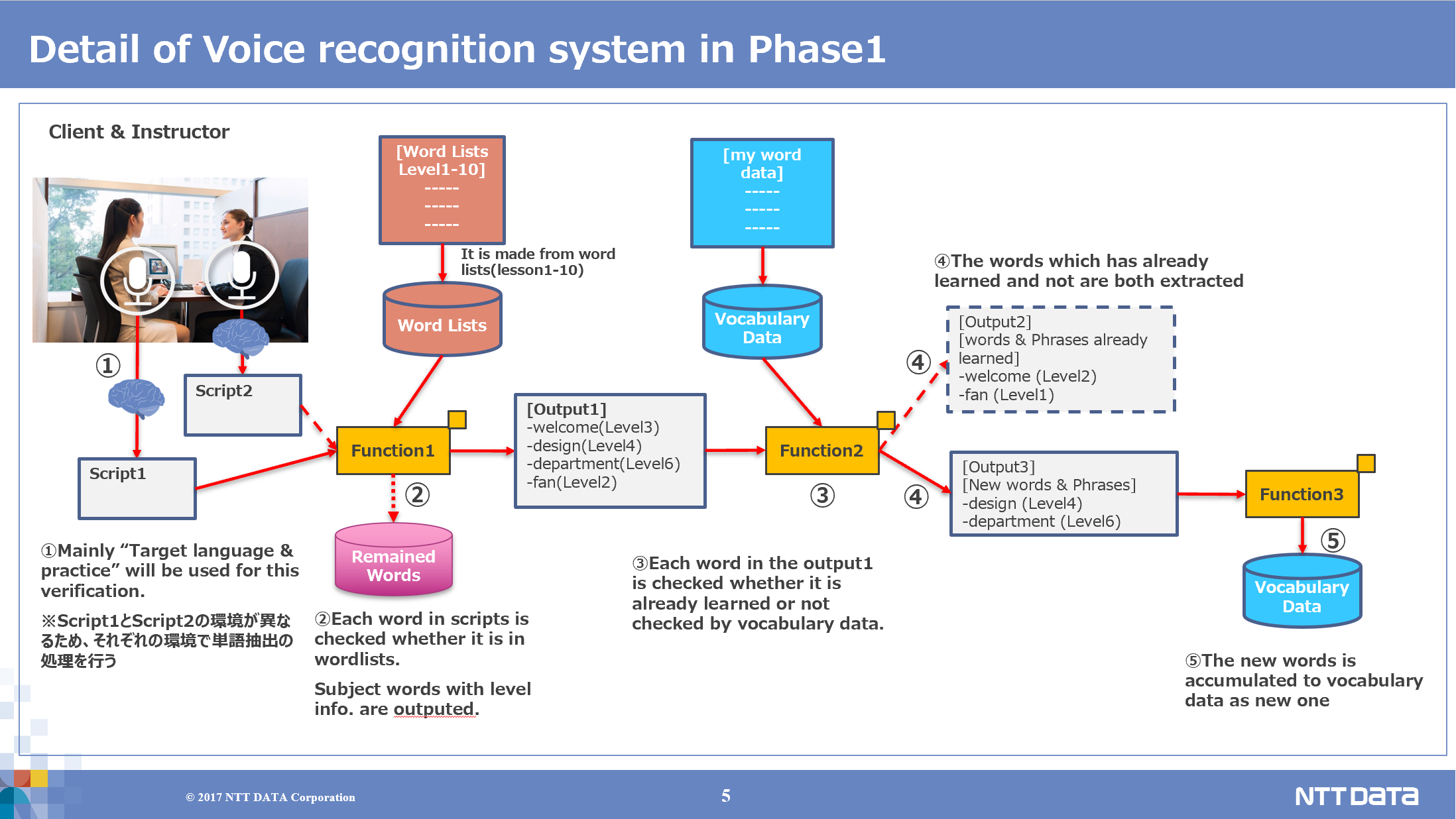
Gaba partnered with NTT Data on a overhaul of the internal IT systems. A Gaba school was opened within the NTT Data headquarters as part of the agreement. NTT Data were trialling software that could transcribe a users speech and wanted to explore ways to use this software in for language learning. This initial pilot testing project trialled training the software with Gaba’s home study audio, level data and vocabulary lists. The hope was that the software would be able to transcribe the learner’s speech during a lesson and identify words that were new to the user. However, this was a future goal and not part of the initial pilot test.
Build
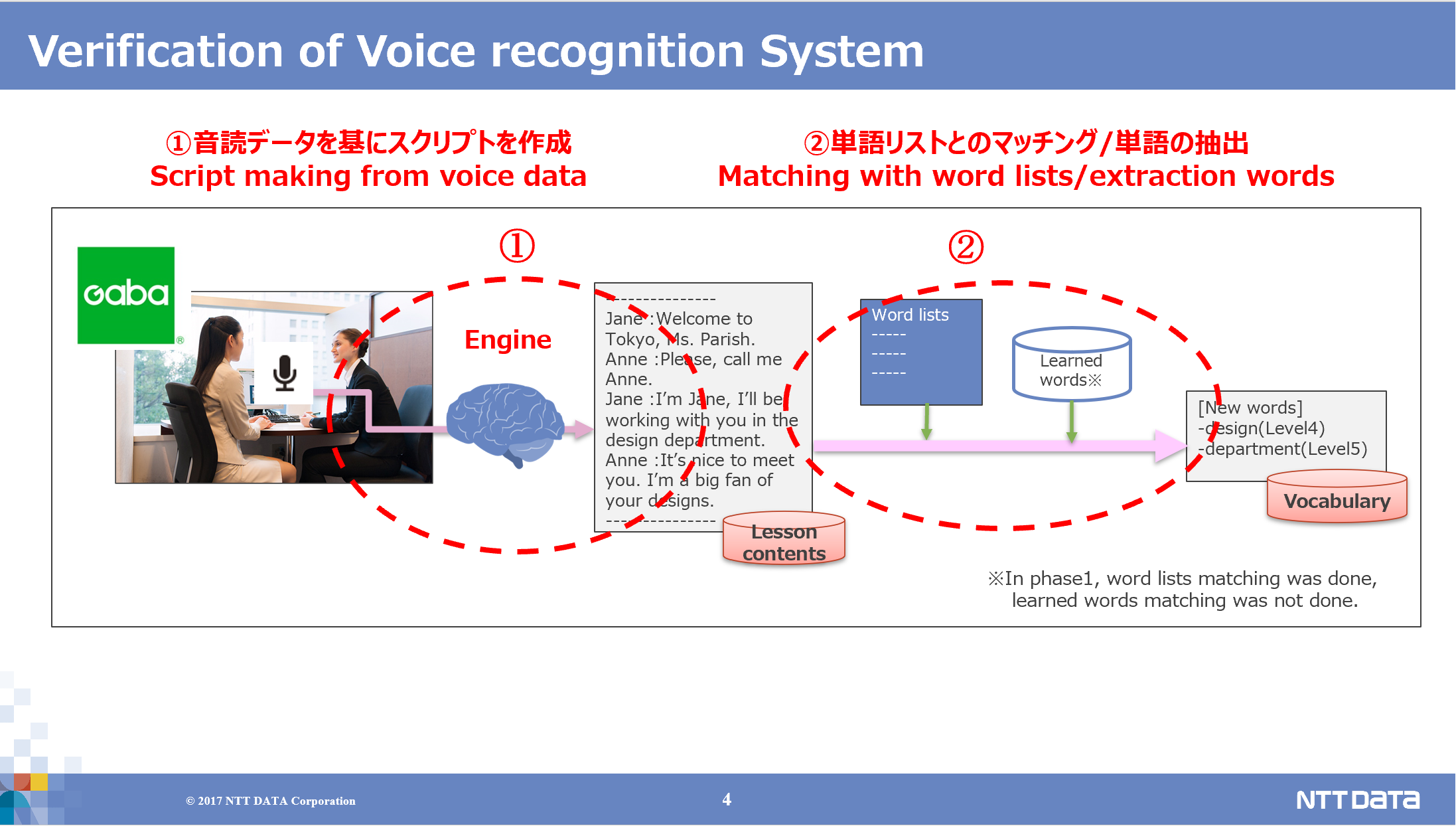
The software was already developeed by NTT Data. They required our home study audio data, word lists and level information to train the voice recognition engine. There were two stages to the test. First, internal colleagues at NTT Data trialled recording themselves reading from a pre-prepared script to measure the accuracy of the engine. Secondly, recording equipment was set up inside the NTT Data in-office school (aka the Tech Learning Studio) and real client’s were recorded taking their lessons and the scripts were analysed. The client’s permission was sought before this took place.
Challenges
The engine was initially trained on native speaker English so had difficulty with some Japanese pronunciation. The hardware for testing inside the Tech Learning Studio was bulky and required a lot of space which a number of clients were not happy about as it made the lesson uncomfortable.
Result
The engine was accurate to a good rate of around 75% overall. There were a number of use cases put forward for further exploration at the end of the trial. These included identifying new words that the client had learned during the lesson and adding them to their flashcards, the identification of client weak areas and subsequent development of personalised training, and the reduction of instructor work through the automated transcription of lesson notes. In the years since this trial took place, companies like Microsoft have developed and release very accurate software for transcribing meetings. There are still a number of use cases for language learning that could still be explored.
Reference
Project press release:https://www.nttdata.com/global/ja/news/release/2017/121500/